웹스크래핑 vs 크롤링
웹 스크래핑(web scraping)은 웹 페이지에서 우리가 원하는 부분의 데이터를 수집해오는 것이다
(한국에서는 같은 작업을 크롤링 crawling 이라는 용어로 혼용해서 쓴다)
* 웹스크레핑은 봇을 이용해 하나의 웹페이지에서 특정 정보를 추출하는 것이고, 웹크롤링은 웹 크롤러 봇으로 무수히 많은 페이지들을 검색 색인에 정리하는 것이다(인덱싱 | Indexing)
* 구글 등 검색엔진은 웹크롤링을 통해 무수히 많은 페이지들에 인덱싱을 했고, 검색을 하면 해당하는 페이지들을 불러서 모은다(일반적인 정보들)
* 참조 : https://www.google.com/intl/ko/search/howsearchworks/crawling-indexing/
Google 검색의 원리 | 크롤링 및 색인 생성
수없이 많은 인터넷 웹페이지에서 정보를 수집하고 구성하기 위해 Google에서 어떤 소프트웨어를 사용하는지 알아보세요.
www.google.com
그래서 우리는 웹스크래핑을 연습해 볼꺼다
웹 스크래핑(Web scrapping)
네이버 영화 정보를 스크래핑 해보자
1. 파이참에서 외부 라이브러리 설치
데이터를 가져오기 위해 requests를 설치한다
HTML코드를 스크래핑 해오기 위해서 beautifulsoup4도 설치한다
2020/09/15 - [아무것도 모르고 시작하는 코딩] - 파이썬(python) requests 라이브러리 설치(feat.파이참) | 아무것도 모르고 시작하는 코딩

2. 영화 제목을 스크래핑 하기
바탕화면 practice 폴더를 만들고 app.py 파일을 만들자
2020/08/16 - [아무것도 모르고 시작하는 코딩] - python(파이썬) 기본 셋팅 | 아무것도 모르고 시작하는 코딩
영화 제목은 네이버 영화에서 가져오려고 한다.
해당 주소는 : movie.naver.com/movie/sdb/rank/rmovie.nhn?sel=cur&date=20200917 이다.

검색창을 키고 선택버튼을 누른 뒤 제목을 클릭하면 선택된 내용이 검색창에 음영 표시가 된다
제목은
<body> - <div id='content'> - <div class='article'> - <div class = 'old_layout old_super_db'> - <div id = 'cbody' class = 'type_1'> - <div id = 'old_content'> - <table cellspacing="0" class="list_ranking"> - <tbody> - <tr> - <td class="title"> - <div class="tit5"> - <a href="/movie/bi/mi/basic.nhn?code=171539" title="그린 북">그린 북</a>
이런 구조를 따라 들어가면 있다.
아래의 내용을 app.py에 붙여넣자
import requests
from bs4 import BeautifulSoup
# 타겟 URL을 읽어서 HTML를 받아오고,
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get('https://movie.naver.com/movie/sdb/rank/rmovie.nhn?sel=cur&date=20200917',headers=headers)
# HTML을 BeautifulSoup이라는 라이브러리를 활용해 검색하기 용이한 상태로 만듦
# soup이라는 변수에 "파싱 용이해진 html"이 담긴 상태가 됨
# 파싱 : 어떤 웹 페이지에서 내가 원하는 데이터를 특정 패턴이나 순서로 추출하여 정보로 가공하는 것
# 이제 코딩을 통해 필요한 부분을 추출하면 된다.
soup = BeautifulSoup(data.text, 'html.parser')
# select를 이용해서, tr들을 불러오기
movies = soup.select('#old_content > table > tbody > tr')
# movies (tr들) 의 반복문을 돌리기
for movie in movies:
# movie 안에 a 가 있으면,
a_tag = movie.select_one('td.title > div > a')
if a_tag is not None:
# a의 text를 찍어본다.
print(a_tag.text)headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
→ 웹스크래핑을 할 때 서버에서 사람이 아닌 봇이 검색하고 있는 것으로 인지하면 '비정상적인 움직임이 발견되어 시스템에 의해 해당 네트워크의 검색을 일시적으로 제한하고 있습니다'라며 스크래핑 하는 것을 막을 수 있다. 따라서 "나는 봇이 아니라 사람이야" 라고 하는 것이 hearders 정보에 User-Agent를 넣어주는 것이다.(headers에는 접속하는사람/프로그램에 대한 정보가 들어있다. headers = {'User-Agent' : '유저정보'})
data = requests.get('주소', headers = headers) → 주소의 페이지에서 데이터를 가져온것을 data라고 하자. 서버에서 headers 정보를 요청하면 우리가 정의한 headers 정보를 줘라
(이때의 data는 태그 기능이 없는 단순한 문자열 입니다. <tr>이라고 해서 tr 태그로 읽는 것이 아니라 그냥 "<tr>"이라는 문자로 가져옵니다)
soup = BeautifulSoup(data.text, 'html.parser') → data를 html화 시키고 html을 파싱(html을 분석하여 구조화)한 것을 soup이라고 하자
movies = soup.select('#old_content > table > tbody > tr') → id가 old_content인 태그 안에 table 안에 tbody 안에 tr 값들을 불러온 것을 movies라고 하자

* 검사창에서 영화제목을 선택하여 표시된 음영 부분에 마우스 오른쪽 버튼을 클릭하여 copy-copy selector를 선택하면 아래와 같은 루트가 복사된다
#old_content > table > tbody > tr:nth-child(2) > td.title > div > a
즉, 이 제목은 id가 old_content인 태그 안에 table태그 안에 tbody태그 안에 tr태그 안에 td.title태그 안에 div태그 안에 a태그에 값이 위치한다는 것을 말해준다
우리는 영화제목을 반복문으로 가져올 것이기 때문에 타이틀이 있는 tr태그까지를 select로 불러온다
for movie in movies:
a_tag = movie.select_one('td.title > div > a') → movie에서 td.title 태그 안에 div 태그 안에 a태그의 값을 선택한 것을 a_tag라고 하자
if a_tag is not None: → a_tag의 값이 비어있지 않으면(존재하면)
print(a_tag.text) → a_tag의 값에서 text 부분을 가져와라(여기의 .text와 beautifulsoup의 .text와는 글씨는 같지만 다른거다)
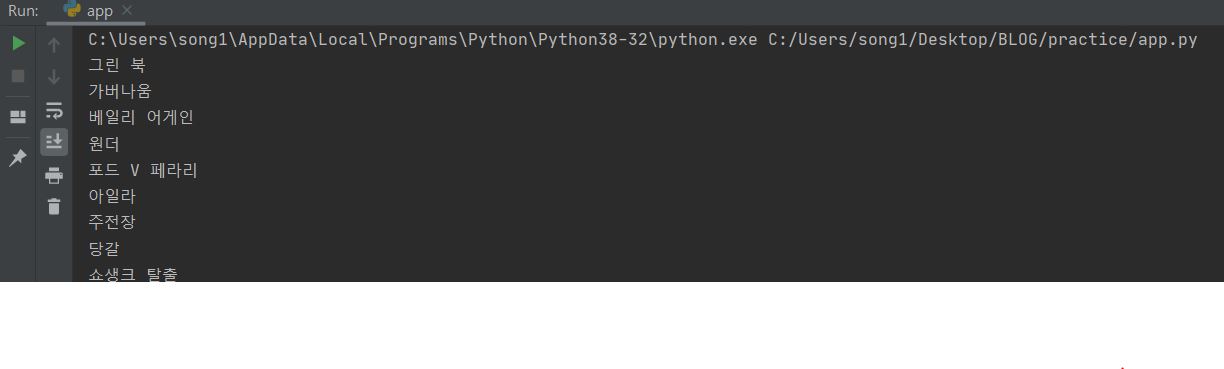
만약 print(a_tag)를 하면 아래와 같이 나온다

글이 길어서 내용이 어려워 보이지만 막상 해보면 쉽게 규칙성을 찾을 수 있다.
다음 포스팅에서 스크래핑의 예제를 몇개 더 해보겠다
끝.
공감 부탁 드려요 :)

'아무것도 모르고 시작하는 코딩' 카테고리의 다른 글
| 윈도우 몽고DB(mongoDB) 설치 방법 | 아무것도 모르고 시작하는 코딩 (0) | 2020.09.22 |
|---|---|
| 야구 순위 웹 스크래핑(a.k.a 크롤링 in Korea) | 아무것도 모르고 시작하는 코딩 (0) | 2020.09.19 |
| 파이썬(python) requests 라이브러리 사용 예시 | 아무것도 모르고 시작하는 코딩 (2) | 2020.09.16 |
| 파이썬(python) requests 라이브러리 설치(feat.파이참) | 아무것도 모르고 시작하는 코딩 (0) | 2020.09.15 |
| python(파이썬) 패키지란? 라이브러리란? | 아무것도 모르고 시작하는 코딩 (0) | 2020.09.14 |